Beginner's guide to Google search console
Google’s new Webmaster tools provide a powerful platform for a wide range of applications. From SEO analysis and indexing reports to overall performance and sitemaps. While the panel is primarily targeted towards webmasters, which probably have the coolest sounding title on the internet, the panel has tools to accommodate a bevy of individuals. Whether you’re an SEO specialist, small business owner, marketer, programmer, or app developer, Google’s new Webmaster tools, rebranded as the Google Search Console, can benefit everyone.
Google's new Webmaster tools provide a powerful platform to uncover issues with your site indexing or site crawlability issues. The search console should be part of any Search optimisation campaign as the primary tool to improving your site.
The new Google Webmaster tools allow you to diagnose issues with the visibility of your content as well as providing information that can help you improve your content and increase visibility.
In this article, we'll be going through the features of these tools and how you can utilize them for your site's benefit.
Adding Your Website to the Search Console
Starting out is easy. Just go to the search console page, and sign into your google account.
After signing in, enter your website's full URL. If your URL has any prefixes such as 'www' or 'https://' be sure to include them as well. Then you'll receive instructions for verifying your ownership of the website. Follow them carefully.
After you're done, you will then be able to use the new Webmaster tools. However, it may take a few days for Google to gather the necessary data about your website before you'll be able to view reports and overviews.
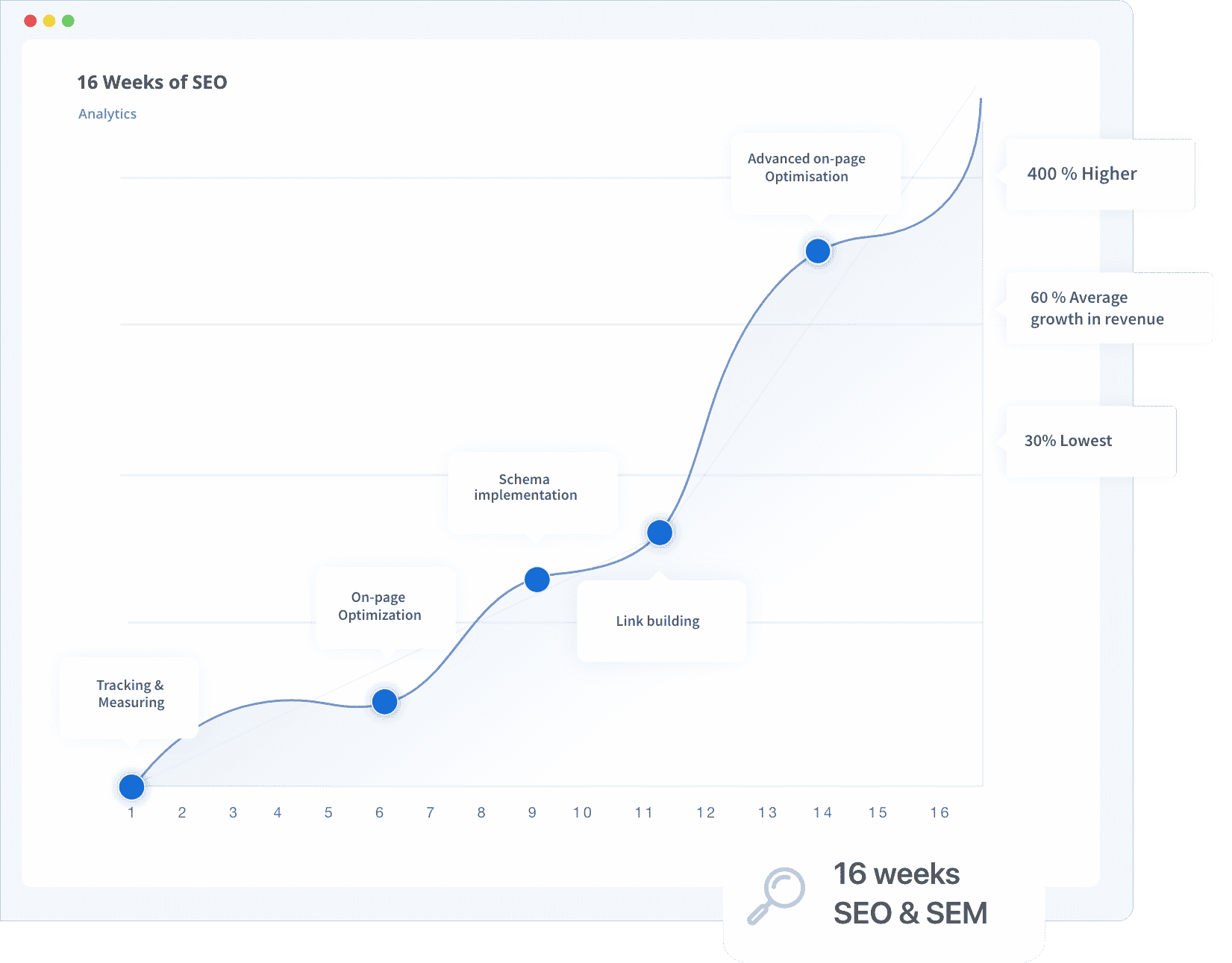
Performance Overview
One of the core features of the new search console is the performance overview. It provides vital metrics, which will show the performance of your site on Google's search results, as well as click-through rates, impressions, clicks and keyword queries.
For example, you could examine the changes in your website's search traffic over time, see exactly where you're getting your traffic, and see which search queries have the highest likelihood of showing your website.
You'll also get information on which queries are being made on smartphones, which can help you better target your SEO for mobile devices.
Additionally, you will be able to easily see which of your web-pages have the best or worst click-through rates, so you'll be able to see which pages are doing well, and which need more attention.
Reading the Overview
The Search Console overview page is your one-stop shop for understanding how your site is performing in Google Search. It condenses important metrics and notifications into a single view, giving you a quick grasp of your website's health. Here's a breakdown of what you can typically find on the overview:
- Performance Chart: This chart summarizes your website's traffic over a chosen time period. It combines data from both Google Search and Discover (if applicable). You'll see key metrics like clicks, impressions, and CTR (Click-Through Rate).
- Search Performance: This section dives deeper into your search traffic. You can see which queries are driving the most clicks and impressions to your site, along with how often your pages appear in search results (impressions).
- Index Coverage: This area highlights any indexing issues Google encounters with your website. It will show you how many pages are indexed, along with any errors or warnings that might prevent proper indexing.
- Mobile Usability: This section focuses on how mobile-friendly your site is. Google prioritizes mobile-friendliness, so it's important to ensure your site offers a good experience on mobile devices.
- Other Features: Depending on your site's functionalities, you might see additional sections like Rich Results or Enhancements. These sections provide information on how Google displays your site in search results, like showing product ratings or recipe snippets.
- Notifications: Keep an eye out for any notifications from Google Search Console. These might alert you to potential issues or suggest improvements for your website.
By understanding these sections and the data they present, you can gain valuable insights into your website's search performance and make informed decisions to improve its visibility and user experience.
Clicks, Impression, CTR and Position Report
This chart within the overview panel provides you with detailed information on the total number of clicks and impressions for your entire site, as well as your average click-through rate and position. Data in this chart is not aggregated by page, but rather for the entire site. This chart can be incredibly useful for seeing how different strategies affect your CTR, the number of impressions, and the other aforementioned statistics.
Sitemaps
The Sitemaps report allows you to see exactly which sitemaps have been processed for your site. The report also notifies you of any errors in processing and allows you to submit new sitemaps.
The Search Console makes the submission of sitemaps easy and helps Google's web crawler to find and index all the publically accessible pages of your site with ease. Using sitemaps can also improve your content tracking and error reporting.
How to Add a Sitemap
Submitting a sitemap for crawling requires a few steps:
- Posting the sitemap to your website
- Making sure the sitemap is using an acceptable format
- Making sure the sitemap is accessible to Googlebot and does not require a login
Once you make sure all of that is covered, you can enter the sitemap's relative URL on the Sitemaps report and click the submit button.
After you submit the sitemap, it should be immediately processed by Google. The search crawler, on the other hand, may take some time to crawl the sitemap's URLs and index them. It's possible that not all listed URLs will be crawled. Whether or not the entire sitemap is crawled will depend on the size of the site, its activity, its traffic, and a number of other factors.
Reading the Sitemap Report
The sitemap report will give you a wealth of information. This information will give you a detailed overview of the sitemap and will allow you to utilize it to the best possible effect.
The information included in the report includes the URL where the sitemap is posted, the original date of submission for the sitemap, and the time that Google last processed the sitemap.
In addition to that information, you will also be given a complete count of the URLs listed. If the sitemap is a sitemap index, it will contain all URLs contained within all referenced sitemaps. If there are duplicate URLs, they will only be counted once.
You will also receive the status of the submit or crawl. This will be one of three values:
- Processed successfully - If you get this result, then your sitemap was successfully loaded and processed, and it will have all contained URLs queued for crawling. This is the result you want.
- Has issues - If you get this result, then your sitemap has at least one error, if not more. Any URLs that can still be retrieved from the sitemap will be queued. This isn't an ideal result, but it might still work.
- Couldn't be fetched - If you get this result, then your sitemap simply couldn't be fetched. It may have the wrong URL, the site may be down at the moment, or the sitemap may just not exist.
The final piece of information that you'll receive in your report is the type of the sitemap. There are three possible types:
- Sitemap - A standard sitemap, containing links to the pages of your site.
- Sitemap index - A sitemap that indexes other sitemaps instead of individual pages.
- Unknown - A file that is not a known type of sitemap, or another type of sitemap that has not been fully processed yet.
Index Coverage Report
This report allows you to see which of your pages were properly indexed, as well as allowing you to troubleshoot any pages that couldn't be properly indexed. The graph displays a number of bars, each representing the number of URLs with a specific status. You're able to share the report by clicking the share button in the same way you were able to share the other report. You may also revoke sharing in the same way.
Top-Level Report
This report displays the current index status of every page on your site that Google has tried to crawl. The pages are grouped by both status as well as reason.
Each page listed will be assigned a general status class, which can be any of these four:
- Error - This page was not indexed due to an error. These are generally the issues you'll want to focus on first. A non-indexed page will not be displayed in Google's search results.
- Warning - This page has an issue that you should look into. A warning will often mean that a page is either currently indexed or was indexed until recently, but has some kind of issue. These aren't as urgent as Errors, but they're still important to handle.
- Excluded - This page has not been indexed, due to either deliberate exclusion or other factors. Usually, this means that it's still in the process of being indexed, or it was deliberately excluded from the index by the person that made the page.
- Valid - This is the result you'll see the most or at least the result that you'll want to see the most. It simply means that your page was indexed properly.
Each status can be further broken down by a specific "reason," which explains why the page is currently affected by that status. The reason also affects the sorting of the data table, allowing you to view columns and rows by reason. A more complete overview of reasons is available in the "Diagnosing Status" section ahead.
There are a number of other criteria which you can use to further sort results and troubleshoot issues.
Via the validation element of an issue, you're able to see the current status of a validation flow initiated by a user. When looking at validation status, you should place more importance on issues that haven't started yet or that have failed.
Another useful element of the report is the URL discovery dropdown filter. This allows you to filter all of the index results based on the exact method that Google used to find the page with its crawler. It allows you to filter by the following criteria:
- All Known Pages - This is the default sort, which displays all URLs that have been discovered by Google's crawler, no matter how they were found.
- All Submitted Pages - This sort will only show pages that have been submitted via a sitemap. This includes sitemaps added via the Search Console, a sitemap ping or a robots.txt file.
- Specific Sitemap URL - This sort will only display pages that are listed within a given sitemap. The sitemap must have been submitted via the Search Console.
Related to the All Submitted Pages and Specific Sitemap URL sorts, sitemaps of sitemaps will return all results of all contained sitemaps. URLs discovered organically through pages submitted via a sitemap are also considered submitted via a sitemap.
Reading the Results
As your site grows, you'll want to see an increasing number of valid pages reflecting that growth.
If instead, you see a steady growth or spike of indexing errors, then that could be caused by a change in your template which introduces new issues, or you may have included a sitemap that includes URLs that can't be accessed by a crawler, such as those with the "noindex" tag, any specified in robots.txt or any that require a login. If none of these are the case, you may need to do additional troubleshooting.
If you see a URL that's marked with a specific issue, but you've already resolved that issue, then Google may not have re-crawled the URL yet. If the last crawl date was before you resolved the issue, then you will have to wait until the URL is next crawled for it to appear resolved. However, if the URL was crawled again after you resolved the issue, then Google was unable to confirm that the issue was fixed, and you will have to make sure that the issue has actually been resolved before the next recrawl.
Troubleshooting the Index Coverage Report
Troubleshooting can help you find out exactly what your issues are, and how to fix them. The first step is checking for any similarity between the sparkline for any specific error and the number of indexing errors. This may provide an idea of which issue may be contributing the most to your total error count.
Fixing Issues
You'll have a table of URLs grouped by the severity of the error or warning. The table also sorts results based on the number of pages affected and current validation status. Google encourages handling each error or warning in the order they're presented in this table.
If you notice an increase in errors, you should keep an eye out for any increases in frequency on the same row, and at the same time, then click the row to see more information via the drilldown page. This page will give you a description of the specific error and will help you ascertain how it should be handled.
Once you've fixed all issues, you can request validation by pressing the "Validate Fix" button in the drilldown. As the validation proceeds, you'll get continuous notifications, however, it's recommended to simply check again after a few days in order to see whether or not the number of errors has been reduced.
Diagnosing Status
When trying to diagnose issues, you'll be given a status, and you will also be given a reason. Reasons provide additional information on what exactly the issue is. A description of each reason follows:
If you see a result that contains the word "submitted," then that just means that you explicitly requested for that URL to be indexed via a sitemap submission. Any other URL is considered not submitted.
Errors
A page that contains an error has not been indexed. There are quite a few different reasons that errors may occur:
- Server Error (5xx) - This error means that the page was requested, but gave Google a 500-level error. This means that your server failed to fulfill a request or that the server has encountered an error.
- Redirect Error - This error means that the provided URL is a redirect error. This could mean a redirect chain exceeding the maximum chain length, a redirect loop, a redirect chain which will eventually exceed the maximum length for URLs or a bad URL in the chain.
- Submitted URL Blocked by robots.txt - This error means that the page was provided for indexing, but was blocked by robots.txt. If this issue persists, try testing the page with Google's robots.txt tester.
- Submitted URL Marked "noindex" - This error means that the page was submitted for indexing, but also has a "noindex" tag, either in its meta tag or in an HTTP response. In order to index this page, you must remove the "noindex" tag or response.
- Submitted URL Seems to be a Soft 404 - This error means that the page submitted for indexing returned a soft 404 error rather than the requested content.
- Submitted URL Returns Unauthorized Request (401) - This error means that the page was submitted for indexing, but when Google attempted to index it, the page returned a 401 error, specifying that they were not authorized to access the page. Either verify the identity of Googlebot or remove the authorization requirements of the page in order to resolve this.
- Submitted URL Not Found (404) - This error means that the URL submitted for indexing simply does not exist.
- Submitted URL Has Crawl Issue - This error means that the page was submitted, but that Google has encountered an unknown crawling issue that isn't covered by any other reason. To fix this, try debugging by using Fetch as Google.
Warnings
Warnings, while not as serious as Errors, still require some attention. Pages with this status may have been indexed, depending on the specific reason given:
- Indexed, Though Blocked by robots.txt - This page was indexed by Google even though it was blocked by robots.txt. This can happen if another outside source links to the page. If your intention was to block all indexing of the page, then you should use the "noindex" tag or use auth to forbid anonymous access. If you don't intend to block the page, then you should update robots.txt in order to unblock it.
- Crawl Anomaly - This warning happens when an unspecified anomaly occurs while Google is fetching the URL. The page has not been indexed. In order to troubleshoot the exact issue, use Fetch as Google and look for fetch issues, or 400/500-level error codes.
- Crawled - This warning only occurs when a page has been crawled by Google but has not been indexed. The URL may be indexed in the future, but the page should not be re-submitted for crawling.
- Discovered - The page is not currently indexed. It has been found by Google but has not yet been crawled or indexed. This typically occurs when the site is overloaded and Google is forced to attempt the crawl at a later date. This can cause the last crawl date to appear empty.
- Alternate Page With Proper Canonical Tag - This page is considered a duplicate of a separate page that is recognized as canonical by Google. However, this page also points to the canonical page correctly. This warning is non-serious and does not need to be resolved.
- Duplicate Page Without Canonical Tag - This page has been duplicated multiple times, but none of the duplicates have been marked as canonical. Google does not think that this specific page is canonical. If this page is meant to be canonical, then you must explicitly mark it as such.
- Duplicate Non-HTML Page - This warning happens when a non-HTML page, such as a PDF file is considered by Google to be a duplicate of a separate page that has been marked as canonical. Generally, only the canonical page will be displayed as a search result. If necessary, you can specify a specific page as canonical via the Link HTTP header.
- Google Chose Different Canonical Than User - This specific page has been marked as canonical, but Google believes that another page would be a more appropriate canonical page. Google has not indexed this page but has indexed the one it considered canonical instead. You should explicitly define this page as a duplicate in order to silence the warning.
- Not Found (404) - When requested, this page gave Google a "Not Found" or 404 error. If the page was moved to another location rather than deleted, it's suggested that you use a 301 redirect to point Google towards the new location.
- Page Removed Because of Legal Complaint - This page was removed due to a legal complaint by a third party.
- Page With Redirect - This URL is a redirect, and has not been added to the index.
- Queued for Crawling - This page has been queued for crawling, but is not currently being crawled. You should check again in a few days for a final status.
- Soft 404 - This means that the page is considered a 404 page, but that it does not contain an explicit 404 code. You should either add a 404 response or add more information in order to confirm that it's not actually a soft 404.
- Submitted URL Dropped - This page was submitted for indexing, but has been removed from the index. The reason for this URL being dropped is unspecified.
- Submitted URL Not Selected as Canonical - Similar to "Google chose different canonical than user" except in this case, you had explicitly requested that this page be indexed.
Valid Pages
Any pages with a valid status have been properly indexed. However, there are still multiple reasons for this status, and in some cases, you may still wish to make changes:
- Submitted and Indexed - This was a page you submitted, either directly or through a sitemap, and it has been properly indexed. This is the ideal status.
- Indexed, Not Submitted in Sitemap - This URL was discovered independently by Google's crawler, and not listed in any sitemap. It's recommended that all important URLs are submitted in a sitemap.
- Indexed; Consider Marking as Canonical - This URL was indexed due to the fact that it has duplicate URLs. We recommend that you explicitly mark this page as canonical in order to prevent future issues and clarify canonicity.
Excluded Pages
These are pages that are not indexed, but Google believes that this was an intentional act on your part. This status has the following reasons:
- Blocked by "noindex" Tag - While Google was attempting to index this page, it ran into an explicit "noindex" tag, and did not index the page. Usually, this is intentional, however, if you did not intend for the "noindex" tag to be used, then simply remove it and Google should index the page the next time it crawls.
- Blocked by Page Removal Tool - This pagewas explicitly blocked by a URL removal request sent to Google. If you are verified as the owner of the website, you may see who submitted the request. These requests are only temporary, and expire after a set period. After this period expires, Googlebot may re-crawl the page and index it even if you do not request it. If your intention was for the page not to be indexed, use a "noindex" tag, remove the page completely, or require authorization.
- Blocked by robots.txt - Googlebot was unable to index this page because it was blocked with a robots.txt file. You may verify that this is the case via the robots.txt tester. However, even if the page is blocked via robots.txt, Google may still be able to gather information about it and index it through other means. If your intention is for the page to not be indexed, use a "noindex" tag and remove the robots.txt block.
- Blocked Due to Unauthorized Request (401) - Googlebot could not access this page due to authorization requirements. When attempting to access the page, it received a 401 response. If you would like Googlebot to be able to crawl this URL, then remove authorization requirements, or explicitly allow access to Googlebot.
Requesting Validation
After you have fixed every instance of a certain issue on your site, you are then able to ask for a validation of your changes from Google. If every instance caught by Google have been resolved, then the issue is marked as fixed and moved directly to the bottom of the report. The new Webmaster tools allow you to track the issue's validation state as a whole, in addition to each individual instance of that particular issue. However, the specific issue is only considered fixed once all instances are resolved.

Written by
Ajay C
Founder & CEO at Mojo Dojo with over 15 years of experience in digital marketing, cybersecurity, and engineering.